5 Buenas Prácticas de Machine Learning Recomendadas Por Expertos
 9 minuto(s)
9 minuto(s)En esta página:
El Machine Learning (Aprendizaje Automático) a veces suele ser un tema de intensa publicidad mediática y cada vez más organizaciones adoptan esta tecnología para manejar sus tareas diarias. Los profesionaes del machine learning pueden presentar la solución, pero mejorar el rendimiento del modelo puede ser un gran desafío a veces. Es algo que viene con la práctica y la experiencia, incluso después de probar todas las estrategías, a menudo no logramos mejorar la precisión del modelo. Por ello en este Post te compartiré 5 Buenas Prácticas de Machine Learning Recomendadas Por Expertos, vamos con ello.
Antes de continuar te invito a leer los siguientes artículos:
- Que es Machine Learning, Historia y otros detalles
- Qué Es Brain JS y Otros Detalles
- APIs de Machine Learning (Aprendizaje Automático) Para Desarrolladores Web
- Que es TensorFlow y Otros Detalles
- 5 Buenas Prácticas de Machine Learning para Desarrolladores en Python
- Como esta presente la Inteligencia Artificial y el Machine Learning en nuestra vida cotidiana
- Como utilizan estas 5 Grandes Empresas el Aprendizaje Automático (Machine Learning)
- Conceptos del Trabajo con Material Design y Machine Learning en Android – Parte 1
- Creando un Bot (Android) para una tienda de Postres (Dialogflow V2 + Kotlin 1.3.72) – Parte 1
- Creando Nuestro Primer Modelo de Machine Learning (Aprendizaje Automático) con TensorFlow – Parte 1
- Puedes leer más artículos en la categoría Machine Learning
Asimismo te invito a escuchar el Podcast: “¿ Que Hago Si No Tengo Los Recursos Para Dedicarme A La Programación ?” y “Ventajas y Desventajas de Usar 2 o Más Monitores Para un Desarrollador” (Anchor Podcast):
| Spotify: | Sound Cloud: | Apple Podcasts | Anchor Podcasts |
 |
 |
 |
 |
Bien ahora continuemos con el Post: 5 Buenas Prácticas de Machine Learning Recomendadas Por Expertos.
Este Post está destinado a ayudar a los principiantes a mejorar la estructura de su modelo de Machine Learning (Aprendizaje Automático), enumerando las mejores prácticas recomendadas por los expertos en aprendizaje automático.
Veamos a continuación las buenas práticas recomendadas por los expertos en Machine Learning (Aprendizaje Automático):
Juega con La Regularización
Es posible que hayas encontrado una situación en la que tus modelos de aprendizaje automático funcionan excepcionalmente bien en tus datos de entranamiento pero no funcionan bien en los datos de prueba. Esto sucede cuando tu modelo sobreajusta sus datos de entrenamiento. Aunque hay muchos métodos para combatir el sobreajuste, como la eliminación de capas, la reducción de la capacidad de la red, la detención anticipada, etc., pero la regulaización supera a todos.
¿Qué es exactamente la regularización?
La regularización es una técnica que evita el sobreajuste reduciendo los coeficientes. Esto da como resultado un modelo simplificado que funciona de manera más eficiente al hacer predicciones. Hay 2 tipos de regularización:
Regularización L1
También se le conoce como regresión de Lasso. Obliga a algunas de las estimaciones de los coeficientes a convertirse exactamente en cero al agregar una penalización al valor absoluto de la magnitud de los coeficientes. Forma un modelo disperso y es útil para la selección de características.
Regularización L2
También se conoce como regresión de Ridge. Penaliza al modelo sumando el cuadrado del valor absoluto de la magnitud de los coeficientes. Por lo tanto, obliga a los coeficientes a tener un valor cercano a cero pero no exactamente cero. Mejora la interpretabilidad del modelo.
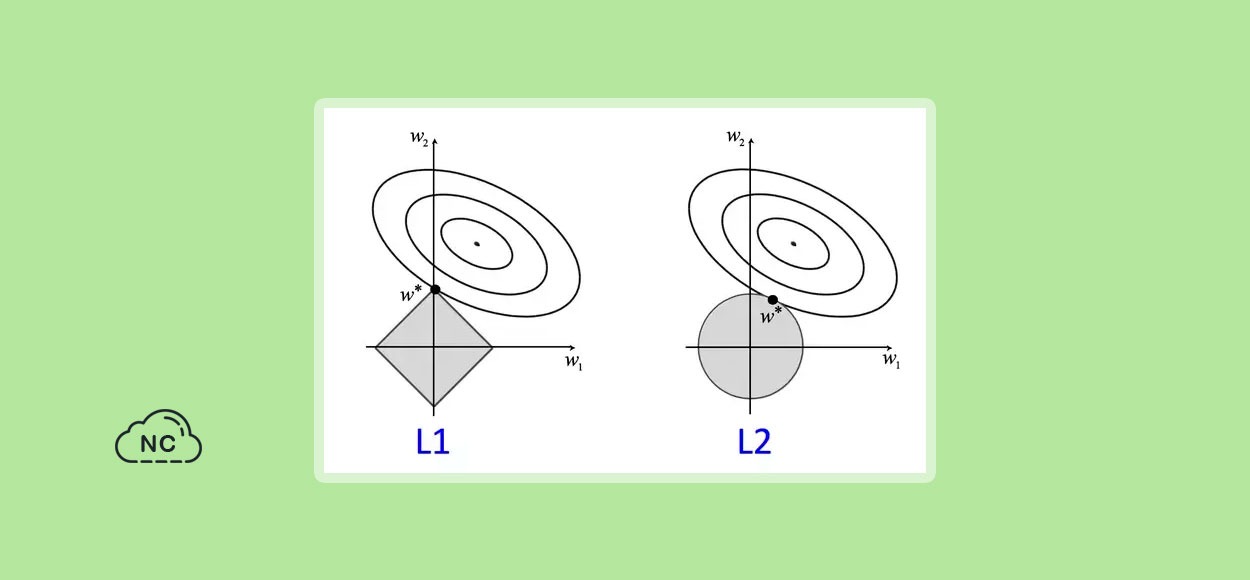
Aunque la regularización de L2 ofrece una predicción más precisa que la de L1, se produce a costa de la potencia de cálculo. Es posible que L2 no sea la mejor opción en caso de valores atípicos, ya que el costo aumenta exponencialmente debido a la presencia de un cuadrado. Por lo tanto, L1 es más robusto en comparación con L2.
Centrarse en los Datos
Las importancia de los datos no se puede ignorar en el mundo del aprendizaje automático. Tanto la calidad como la cantidad de los datos pueden conducir a un mejor rendimiento del modelo. A menudo lleva tiempo y es más complejo que crear los propios modelos de aprendizaje automático. Este paso a menudo se denomina preparación de datos. Se puede clasificar en los siguientes pasos:
- Articular el problema: Para evitar complicar demasiado tu proyecto, intenta obtener un conocimient profundo del problema subyacente que estás tratando de resolver. Categoriza tu problema en clasificación, regresión, agrupación o recomendación, etc. Esta segmentación simple puede ayudarte a recopilar el conjunto de datos relevante que sea más adecuado para tu escenario.
- Recopilación de datos: La recopilación de datos puede ser una tarea tediosa. Como sugiere el nombre, es la recopilación de datos históricos para encontrar patrones recuerrentes. Se puede clasificar en datos estructurados (archivos de Excel o .csv) y datos no estructurados (fotos, videos, etc.). Algunas de las fuentes famoras para tomar prestando su conjunto de datos son:
- Exploración de datos: Este paso implica identificar los problemas y patrones en el conjunto de datos con la ayuda de ténicas estadísticas y de visualización. Debes realizar varias tareas, como detectar los valores atípicos, identifcar la distribución de datos y la relación entre las características, buscar valores inconsistentes y faltantes, etc. Microsoft Excel es una herramienta manual popular que se usa para este paso.
- Limpieza y validación de datos: Implica eliminar la información irrelevante y abordar los valores faltantes mediante varias herramientas de imputación. Identifica y eliminar los datos redundantes. Hay muchas opciones de código abierto como OpenRefine, Pandera, etc., están disponibles para limpiar y validar datos.
Identificar Los Errores
Es muy importante que mantengamos un registro de qué tipo de errores está cometiendo nuestro modelo con fines de optimización. Esta tarea se puede realizar por medio de varios gráficos de visualización dependiendo del tipo de problema a resolver. Algunos de ellos se discuten a continuación:
Clasificación
Los modelos de clasificación son el subconjunto del aprendizaje supervisado que clasifica la entrada en una o más categorías según la salida generada. Los modelos de clasificación se pueden visualizar mediante diversas herramientas.
Informe de clasificación
Es una métrica de evaluación que muestra la precisión, la puntuación F1, la recuperación y el soporte. Da una buena comprensión general del rendimiento de tu modelo.
Matriz de Confusión
Compara los valores verdaderos con los predichos. En comparación con el informe de clasificación, proporciona una visión más profunda de la clasificación de los puntos de datos individuales en lugar de las puntuaciones de nivel superior.
Regresión
Un modelo de regresión predice la relación entre las variables independientes y dependientes proporcionando la función deseada. Realiza las predicciones en espacio continuo.
Gráficas de Residuales
Muestra las variables independientes a lo largo del eje horizontal y los residuales en el eje vertical. Si los puntos de datos están dispersos aleatoriamente a lo largo del eje horizontal, entonces un modelo lineal es un ajuste más apropiado y viceversa.
Gráficos de error de predicción
Muestra el objetivo real frente a los valores predichos para dar una idea de la varianza. Una línea de 45 grados es donde la predicción coincide exactamente con el modelo.
Ingeniería de Características
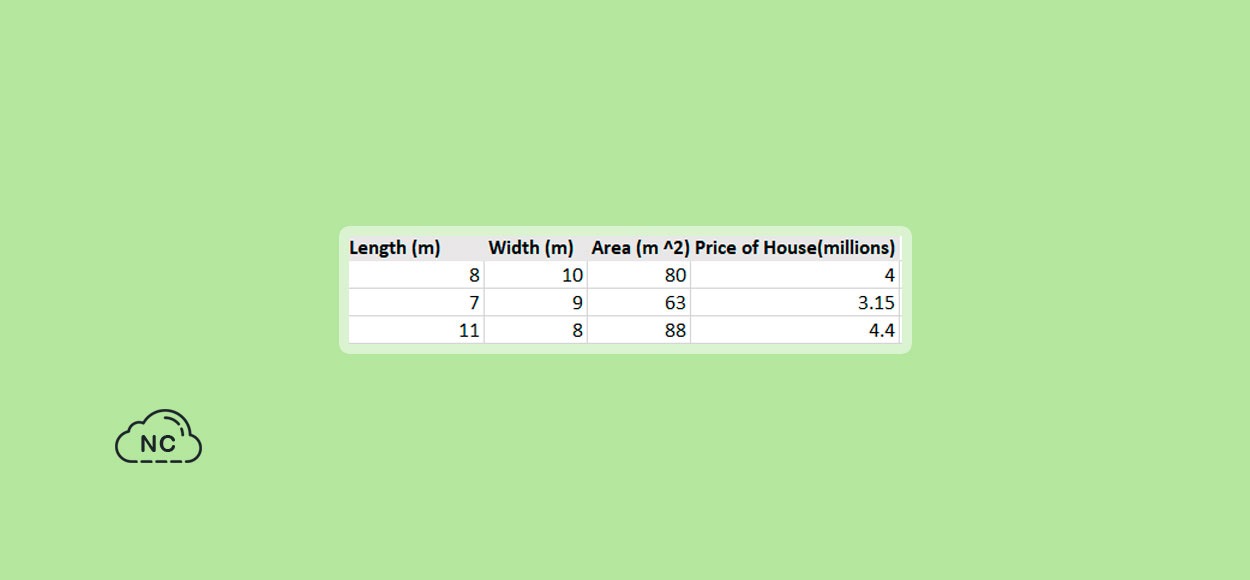
Es otra técnica esencial para mejorar el rendimiento del modelo y acelerar las transformación de datos. La ingeniería de funciones implica infundir nuevas funciones en tu modelo a partir de funciones que ya están disponibles. Puede ayudarnos a identificar las características sólidas y eliminar las correlacionadas o redundantes. Sin embargo, requiere experiencia y dominio, puede no ser factible si nuestra línea de base inicial ya inlcuye un conjunto diverso de características. Entendámosolo a partir de un ejemplo. Considera que tienes un conjunto de datos que contiene la longitud, el ancho y el precio de una casa de la siguiente manera:

En lugar de uar el conjunto de datos anterior, podemos introducir otra característica llamada “Area” y medir solo el impacto de esa variable en el precio de la casa. Este proceso se incluye en la categoría de Feature Creation (Creación de características).
Del mismo modo, la Feature Transformation (Transformación de características) y la Feature Extraction (Extracción de características) pueden resultar valiosas según el dominio de nuestro proyecto. La transformación de características implica aplicar la función de transformación en una función para una mejor visualización, mientras que en la extracción de características comprimimos la cantidad de datos extrayendo solo las características relevantes.
Aunque el Feature Scaling (Escalado de características) también es parte de la Feature Engineering (Ingeniería de características), lo menciono por separado para centrarme en su importancia. Feature Scaling es el método utilizado para normalizar el rango de características y variables independientes. ¿Por qué es tan importante este paso? La mayoría de los algoritmos, como las regresiones lineales, la regresión logística y las redes neuronales, utilizan el descenso de gradiente como técnica de optimización. El descenso del gradiente depende en gran medida del rango de características para determinar el tamaño del paso hacia los mínimos, pero la mayoría de nuestros datos varían drásticamente en términos de rangos. Esto nos obliga a normalizar o estandarizar nuestros datos antes de introducirlos en el modelo.
Las dos técnicas más importantes son:
Normalización
La normalización es la técnica para vincular tus datos típicamente entre rango [0,1] pero también puede definir tu rango [a,b] donde a y b son números reales.
Estandarización
La estandarización transforma tus datos para que tengan una media de 0 y una varianza de 1. Primero calculamos la desviación estándar y la media de la característica y luego calculamos el nuevo valor usando la siguiente formula:
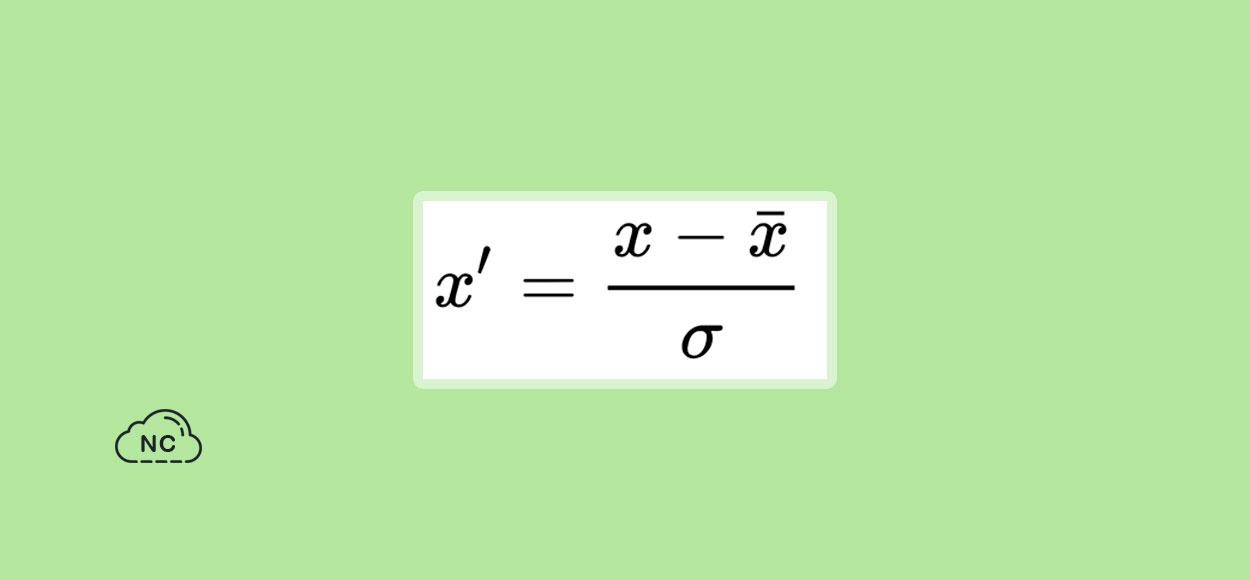
Ha habido mucho debate para determinar cuál es mejor y algunos hallazgos mostraron que para una distribución gaussiana, la estandarización fue más útil ya que no se vió afectada por la presencia de valores atípicos y viceversa. Pero, depende del tipo de problema en que estés trabajando. Por lo tanto, es muy recomendable probar ambos y comparar el rendimiento para descubrir qué funciona mejor para ti.
Ajustes de Hiperparámetros
Los hiperparámetros son un conjunto de parámetros que el propio algoritmo no puede aprender y se establecen antes de que comience el proceso de aprendizaje, por ejemplo, tasa de aprendizaje (alfa), tamaño del mini lote, número de capas, número de unidades ocultas, etc. El ajuste de hiperparámetros (Hyperparameter tuning) se refiere al proceso de seleccionar los hiperparámetros más óptimos para un algoritmo de aprendizaje que minimiza la función de pérdida.
En una red más simple, experimentamos con versiones separadas del modelo y con diferentes combinaciones de los hiperparámetros, pero esta puede no ser la opción adecuada para las redes más complejas. En ese caso, hacemos la selección óptima basándonos en el conocimiento previo. Algunos de los métodos de ajuste de hiperparámetros ampliamente utilizados para hacer una selección adecuada del rango de un espacio de hiperparámetros son los siguientes:
Búsqueda en cuadrícula
Es el método tradicional y más utilizado para el ajuste de hiperparámetros. Implica seleccionar el mejor conjunto de la cuadrícula que contiene todas las combinaciones posibles de hiperparámetros. Sin embargo, necesita más poder computacional y tiempo para realizar su operación.
Búsqueda aleatoria
En lugar de probar todas las combinaciones, selecciona el conjunto de valores de forma aleatoria de la cuadrícula para encontrar los más óptimos. Ahorra energía y tiempo computacional innecesarios en comparación con la búsqueda en cuadrícula. Dado que no se utiliza alguna inteligencia, la suerte juega un papel y produce una gran variación.
Búsqueda bayesiana
Se utiliza en el aprendizaje automático aplicado y supera a la búsqueda aleatoria. Hace uso del teorema de Bayes y tiene en cuenta el resultado de la iteración anterior para mejorar el resultado de la siguiente. Necesita una función objetivo que minimice la pérdida. Funciona creando un modelo de probabilidad sustituto de la función objetivo, luego encuentra los mejores hiperparámetros para el modelo sustituto, luego se aplica al modelo original y actualiza el modelo sustituto, y estima la función objetivo. Este proceso se repite hasta que encontramos la solución óptima para el modelo original. Se necesita menos iteración, pero se requiere más tiempo para cada iteración.
Conclusión
El aprendizaje automático (machine learning) y el aprendizaje profundo (deep learning) requieren buenos recursos computacionales y experiencia en la materia. La creación de modelos ML (Machine Learning) es un proceso iterativo que implica la realización de varios consejos para mejorar el rendimiento general del modelo. En este Post he compartido algunas de las mejores prácticas recomendadas por los expertos en ML para acceder a las deficiencias de tu modelo actual. Sin embargo, como siempre digo, todo llega con suficiente práctica y paciencia, así que sigue aprendiendo de tus errores.
Nota(s)
- No olvides que debemos usar la Tecnología para hacer cosas Buenas por el Mundo.
Síguenos en las Redes Sociales para que no te pierdas nuestros próximos contenidos.
- Machine Learning
- 27-09-2022
- 28-09-2022
- Crear un Post - Eventos Devs - Foro










 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad. Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)