Como hacer Ciencia de Datos (Data Science) a los productos de una Tienda de Postres – Parte 13
 5 minuto(s)
5 minuto(s)Demo
En este Post vamos a continuar con la parte anterior llamada Como hacer Análisis a los productos de una Tienda de Postres mediante Data Science – Parte 12 en donde terminamos de filtrar los Datos de Postres Consumidos según el Horario de la Tienda, específicamente las Ventas de Postres por la Noche (6PM – 11PM), estos datos los especifique en la Parte 2 de este tutorial y en este Post continuaremos analizando los siguientes datos.
Partes

Antes de continuar con este Post te recomiendo leer los siguientes artículos:
- Errores que impiden hacer uso de las mejores prácticas de la Ciencia de Datos (Data Science)
- Como usar el Lenguaje de Programación R en Jupyter Notebook
- Que es la Ciencia de Datos (Data Science)
Continuemos con el Post: Como hacer Análisis a los productos de una Tienda de Postres mediante Data Science – Parte 13
Los siguientes datos que analizaré, son los Datos de Bebidas Consumidas según el Horario de la tienda, específicamente las Ventas de Bebidas por la Mañana (9AM – 12PM).
Para mantener un orden de mis consultas voy a crear un nuevo archivo, para esto dentro de Jupyter voy a File > New Notebook > Python 3
En mi nuevo Documento analizaré las Ventas de Bebidas por la Mañana (9AM – 12PM).
Datos de Bebidas Consumidas según el Horario de la tienda: Ventas de Bebidas por la Mañana (9AM – 12PM)
Lo primero que haré es importar la librería pandas y le asigno el nombre de variable pd
|
1 2 3 4 |
import pandas import pandas as pd |
Paso seguido creo una variable con el nombre ventas y en su interior hago la lectura del archivo ventas.json en donde se encuentran todas las ventas realizadas durante el día en la Tienda de Postres. Además crearé una variable llamada datos y dentro de ella defino las columnas para mi tabla en donde mostraré las ventas realizadas por la Mañana, estas columnas son id, producto, categoria, cliente, dni, fnacimientocliente, precio, img, created_at y updated_at
|
1 2 3 4 5 6 7 8 9 |
ventas = pandas.read_json("ventas.json", orient="split", encoding="utf-8") datos = pd.DataFrame( ventas, columns = ['id', 'producto', 'categoria', 'cliente', 'dni', 'fnacimientocliente', 'precio', 'img', 'created_at', 'updated_at']) datos |
Nota: El archivo ventas.json lo exporte en la Parte 5 de este tutorial.
Para la consulta haré uso de la columna categoria del archivo ventas.json, ya que necesito saber la categoría a la cual pertenece un producto.
Bueno con el código anterior voy a imprimir una Tabla con todas las ventas realizadas en la Tienda de Postres, para esto presiono el botón Run y obtengo la Tabla con las columnas que especifique en la variable datos
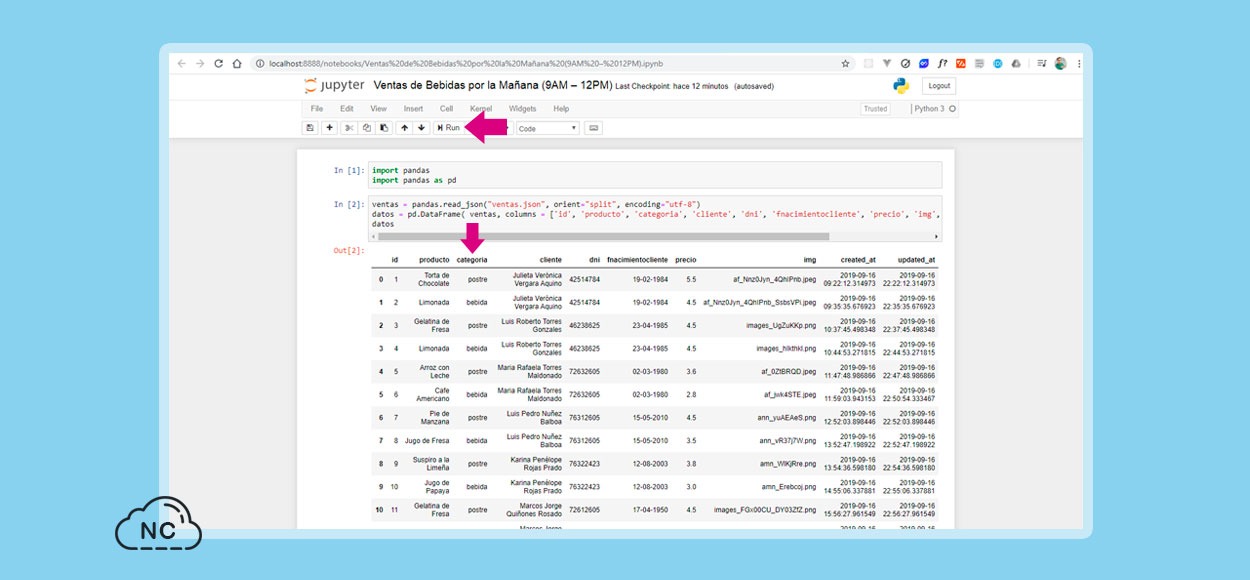
Ahora voy a obtener las ventas realizadas en el horario de la mañana voy usar la columna de tipo fecha o timestamp llamada created_at esta contiene la hora, fecha, minuto, segundos y milisegundos de una venta realizada.
|
1 2 3 |
datos['created_at'] = pd.to_datetime(datos['created_at']) |
Voy a declarar 3 variables, una llamada hi (Hora inicial), otra llamada hf (Hora final) y categoria (Categoría del producto).
Dentro de la variable hi colocaré el valor de las 9 AM (09:00:00.000000) y en la variable hf colocaré el valor 12 PM (12:00:00.000000), las horas las especifico en formato de 24 horas, en la variable categoria coloco el valor bebida, ya que es la categoría de productos que quiero analizar.
|
1 2 3 4 5 |
hi = '2019-09-16 09:00:00.000000' hf = '2019-09-16 12:00:00.000000' categoria = 'bebida' |
Nota: Las ventas que estoy analizando en todo el Tutorial se realizaron el día 16-09-2019
Como quiero leer las ventas realizadas de los productos de la categoría bebidas, voy a usar la columna categoria, esta columna contiene el nombre de la categoría de un producto.
|
1 2 3 |
datos['categoria'] = datos[['categoria']] |
Creo una variable con el nombre filtrar y dentro de ella hago uso de operadores lógicos en Python para filtrar las ventas realizadas desde las 9AM hasta las 12PM, para esto paso las variables hi y hf que contienen los rangos de horarios a analizar y al final la variable categoria.
Voy a consultar si la columna created_at es mayor o igual a la Hora inicial (hi) y si la columna created_at es menor o igual a la Hora final (hf), y al final consulto si la columna categoria es igual al valor bebida, el cual asigne a la variable categoria.
|
1 2 3 |
filtrar = (datos['created_at'] >= hi) & (datos['created_at'] <= hf) & (datos['categoria']== categoria) |
Defino una variable llamada resultado y en su interior obtendré las ventas filtradas haciendo uso del método .loc al cual le paso la variable filtrar
|
1 2 3 4 |
resultado = datos.loc[filtrar] resultado |
Presiono el botón Run y obtengo una tabla con las ventas realizadas de 9 AM a 12 PM, es decir en el Turno Mañana de los productos correspondientes a la categoría bebidas.
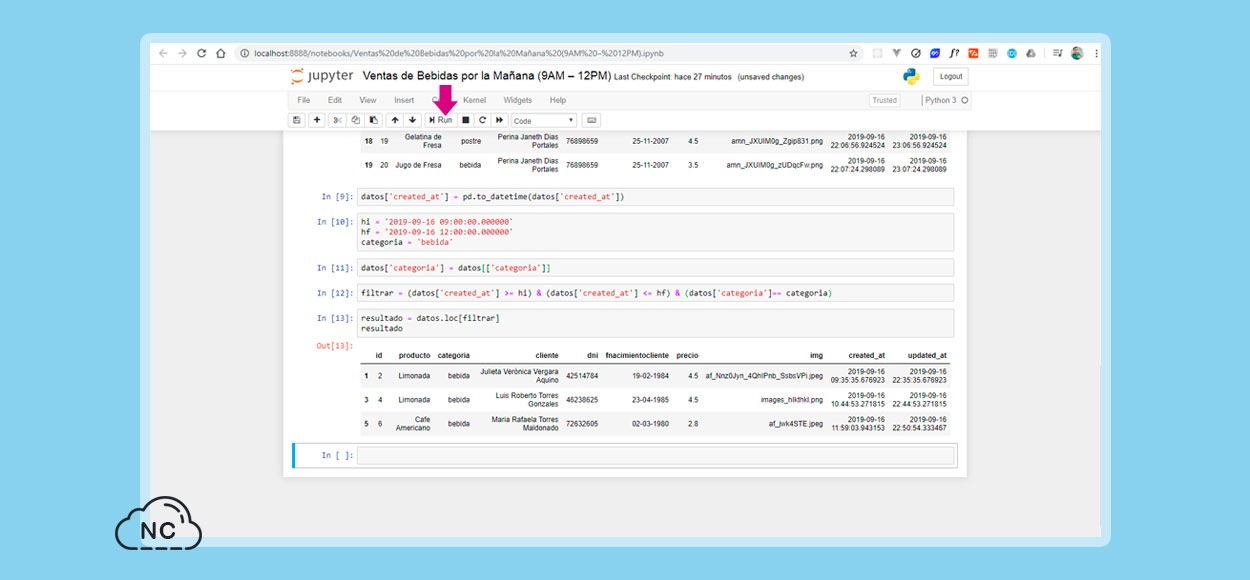
Puedes ver en la imagen anterior que obtuve solo 3 bebidas, es una cantidad menor a otras consultas anteriores, esto es porque seleccione solos productos pertenecientes a la categoría bebida.
Ahora los datos de la tabla con las ventas realizadas en la Mañana pertenecientes a la categoría bebida los voy a mostrar en un gráfico Plot, para esto importo la librería matplotlib.pyplot y le doy el nombre de variable plot
Le especifico el ancho y alto 20, 11 del gráfico, estas medidas son en pulgadas
|
1 2 3 4 |
import matplotlib.pyplot as plot plot.rcParams["figure.figsize"] = 20,11 # ancho: 20 , alto: 11 |
Paso seguido le paso la variable resultado la cual había creado anteriormente y le indico que imprima las columnas producto y created_at
|
1 2 3 |
resultado.plot(x="producto", y="created_at") |
Hago clic en el botón Run y se me imprime un gráfico Plot con las ventas realizadas de 9 AM a 12 PM pertenecientes a la categoría bebida.
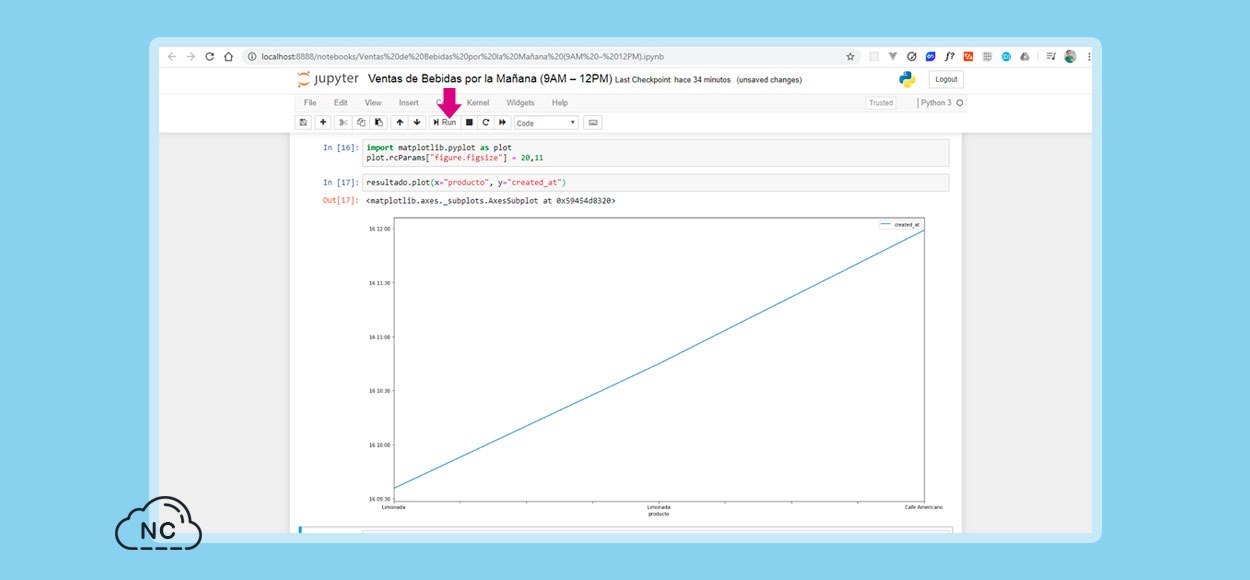
Te compartiré el código completo
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import pandas import pandas as pd # Lectura del archivo ventas.json ventas = pandas.read_json("ventas.json", orient="split", encoding="utf-8") datos = pd.DataFrame( ventas, columns = ['id', 'producto', 'cliente', 'dni', 'fnacimientocliente', 'precio', 'img', 'created_at', 'updated_at']) datos # Obtener Ventas realizas de 9PM a 12PM datos['created_at'] = pd.to_datetime(datos['created_at']) hi = '2019-09-16 09:00:00.000000' hf = '2019-09-16 12:00:00.000000' categoria = 'bebida' # Obtener los productos pertenecientes a la categoría 'bebida' datos['categoria'] = datos[['categoria']] filtrar = (datos['created_at'] >= hi) & (datos['created_at'] <= hf) & (datos['categoria']== categoria) resultado = datos.loc[filtrar] resultado # Crear un Gráfico Básico (Plot) con los datos Filtrados import matplotlib.pyplot as plot plot.rcParams["figure.figsize"] = 20,11 # ancho: 20 , alto: 11 resultado.plot(x="producto", y="created_at") |
Bien eso es todo en este Post, hemos realizado el análisis de todas las ventas realizadas durante la mañana (9AM – 12PM), pertenecientes a la categoría bebida.
Ten Paciencia, lo que quiero es que entiendas todo el proceso de como funciona la Ciencia de Datos (Data Science) en una caso similar a la realidad.
Nota (s)
- En el siguiente capitulo terminare con el análisis de los Demás Datos pendientes.
- Más adelante usaré herramientas de Visualización de Datos más especializadas en el área.
Síguenos en nuestras Redes Sociales para que no te pierdas nuestros próximos contenidos.
- Data Science (Ciencia de Datos)
- 10-03-2020
- 13-08-2021
- Crear un Post - Eventos Devs - Foro










 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
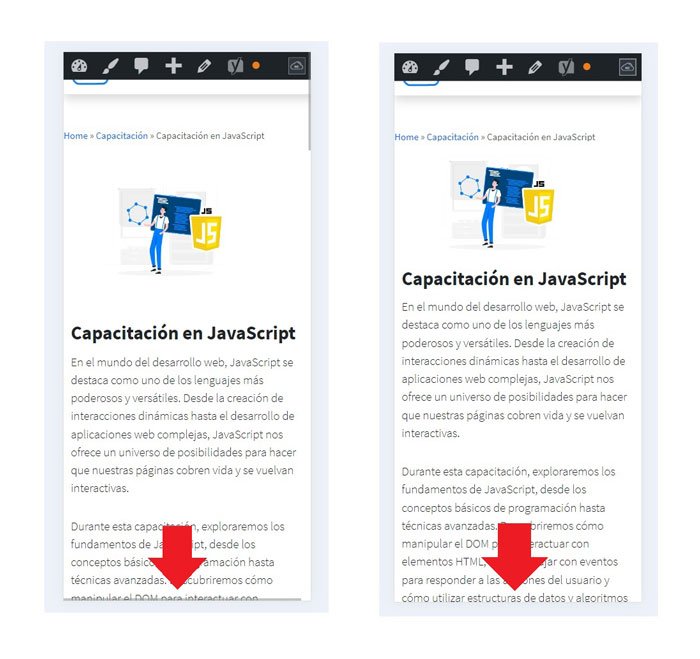 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad. Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)