Tipos de Datos en PostgreSQL – Parte 3 (Final)
 12 minuto(s)
12 minuto(s)En la parte anterior pudimos ver otro segundo grupo de tipos de datos que tiene PostgreSQL. Entre los tipos de datos que vimos están los tipos de fecha/hora, tipo booleano, tipos enum, tipos direcciones de red y tipos strings de bits. En este post que consta de 3 parte estamos viendo datos por datos, la intención es que tengas un aprendizaje óptimo y cuando desarrolles proyectos con PostgreSQL, no se te falta información. Porsupuesto que hay más cosas que podriamos aprender sobre los tipos de datos en PostgreSQL, pero es mejor aprenderlos sobre la marcha de construcción de un proyecto. En esta tercera y última parte te compartiré un último grupo de Tipos de Datos en PostgreSQL, vamos con ello.
Parte

Asimismo, te invito a escuchar el Podcast: “Como Mantenerte Motivado Para Seguir Programando” y “Consejos Para Entrenar Tu Memoria de Programador” (Anchor Podcast):
| Spotify: | Sound Cloud: | Apple Podcasts | Anchor Podcasts |
 |
 |
 |
 |
Bien ahora continuemos con el Post: Tipos de Datos en PostgreSQL – Parte 3 (Final).
Tipos búsqueda de texto
PostgreSQL proporciona dos tipos de datos que están diseñados para admitir la búsqueda de texto completo, que es la actividad de buscar a través de una colección de documentos en lenguaje natural para ubicar los que mejor coinciden con una consulta . El tipo tsvector representa un documento en un formato optimizado para la búsqueda de texto; el tipo tsquery representa de manera similar una consulta de texto.
Un valor tsvector es una lista ordenada de distintos lexemas, que son palabras que se han normalizado para fusionar diferentes variantes de la misma palabra. La clasificación y la eliminación de duplicados se realizan automáticamente durante la entrada, veamos el siguiente ejemplo:
|
1 2 3 4 5 6 |
SELECT 'un gato gordo se sentó en una estera y se comió una rata gorda'::tsvector; tsvector ---------------------------------------------------- 'a' 'y' 'ate' 'gato' 'gordo' 'mat' 'en' 'rata' 'sat |
Para representar lexemas que contengan espacios en blanco o puntuación, rodéalos con comillas:
|
1 2 3 4 5 6 |
SELECT $$el lexema ' ' contiene espacios$$::tsvector; tsvector ------------------------------------------- ' ' 'contiene' ' lexema' 'espacios' 'el' |
Pasemos al tipo de dato UUID.
Tipo UUID
El tipo de datos uuid almacena identificadores únicos universales (UUID) según lo definido por RFC 4122, ISO/IEC 9834-8:2005 y estándares relacionados. (Algunos sistemas se refieren a este tipo de datos como un identificador único global o GUID, en su lugar.) Este identificador es una cantidad de 128 bits que se genera mediante un algoritmo elegido para que sea muy poco probable que alguien más en el universo conocido genere el mismo identificador utilizando el mismo algoritmo. Por lo tanto, para los sistemas distribuidos, estos identificadores brindan una mejor garantía de unicidad que los generadores de secuencias, que solo son únicos dentro de una sola base de datos.
Un UUID se escribe como una secuencia de dígitos hexadecimales en minúsculas, en varios grupos separados por guiones, específicamente un grupo de 8 dígitos seguido de tres grupos de 4 dígitos seguidos de un grupo de 12 dígitos, para un total de 32 dígitos que representan el 128 bits Un ejemplo de un UUID en esta forma estándar es:
|
1 2 3 4 |
# UUID a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11 |
PostgreSQL también acepta las siguientes formas alternativas de entrada:
- Uso de dígitos en mayúsculas
- Formato estándar entre llaves,
- Omisión de algunos o todos los guiones,
- Adición de un guión después de cualquier grupo de cuatro dígitos.
Veamos los siguientes ejemplios:
|
1 2 3 4 5 6 7 |
A0EEBC99-9C0B-4EF8-BB6D-6BB9BD380A11 {a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11} a0eebc999c0b4ef8bb6d6bb9bd380a11 a0ee-bc99-9c0b-4ef8-bb6d-6bb9-bd38-0a 11 {a0eebc99-9c0b4ef8-bb6d6bb9-bd380a11} |
La salida siempre se mantiene en su forma estándar.
Tipo XML
El tipo de datos xml se puede utilizar para almacenar datos XML. Su ventaja sobre el almacenamiento de datos XML en un campo text es que comprueba que los valores de entrada estén bien formados, y existen funciones de soporte para realizar operaciones de tipo seguro en él. El uso de este tipo de datos requiere que la instalación se haya creado con configure –with-libxml.
El tipo xml puede almacenar “documentos” bien formados , según lo define el estándar XML, así como fragmentos de “contenido”, que se definen por referencia al “nodo de documento” más permisivo del modelo de datos XQuery y XPath. Aproximadamente, esto significa que los fragmentos de contenido pueden tener más de un elemento de nivel superior o nodo de carácter. La expresión xmlvalue IS DOCUMENT se puede usar para evaluar si un valor xml particular es un documento completo o solo un fragmento de contenido.
Para producir un valor de tipo xml a partir de datos de caracteres, usa la función xmlparse:
|
1 2 3 |
XMLPARSE ( { DOCUMENT | CONTENT } value) |
Ejemplos:
|
1 2 3 4 |
XMLPARSE (DOCUMENT '<?xml version="1.0"?><book><title>Manual</title><chapter>...</chapter></book>') XMLPARSE (CONTENT 'abc<foo>bar</foo><bar>foo</bar>') |
Si bien esta es la única forma de convertir cadenas de caracteres en valores XML de acuerdo con el estándar SQL, las sintaxis específicas de PostgreSQL también pueden ser usadas:
|
1 2 3 4 |
xml '<foo>bar</foo>' '<foo>bar</foo>'::xml |
El tipo xml no valida los valores de entrada contra una declaración de tipo de documento (DTD), incluso cuando el valor de entrada especifica una DTD. Actualmente tampoco hay soporte integrado para validar contra otros lenguajes de esquema XML como XML Schema.
Tipos JSON
Los tipos de datos JSON son para almacenar datos JSON (Notación de objetos de JavaScript), como se especifica en RFC 7159. Dichos datos también se pueden almacenar como text, pero los tipos de datos JSON tienen la ventaja de exigir que cada valor almacenado sea válido de acuerdo con las reglas JSON.
PostgreSQL ofrece dos tipos para almacenar datos JSON: json y jsonb. Para implementar mecanismos de consulta eficientes para estos tipos de datos, PostgreSQL también proporciona el tipo de datos jsonpath.
Los tipos de datos json y jsonb aceptan conjuntos de valores casi idénticos como entrada. La principal diferencia práctica es la eficiencia. El tipo de datos json almacena una copia exacta del texto de entrada, que las funciones de procesamiento deben analizar en cada ejecución; mientras que los datos jsonb se almacenan en un formato binario descompuesto que hace que sea un poco más lento de ingresar debido a la sobrecarga de conversión adicional, pero significativamente más rápido de procesar, ya que no se necesita volver a analizar. El tipo de dato jsonb también es compatible con la indexación, lo que puede ser una ventaja significativa.
Tipo Array
PostgreSQL permite que las columnas de una tabla se definan como arrays multidimensionales de longitud variable. Se pueden crear arrays de cualquier tipo base integrado o definido por el usuario, tipo de enumeración, tipo compuesto, tipo de rango o dominio.
Para ilustrar el uso de tipos de matriz, creamos la siguiente tabla:
|
1 2 3 4 5 6 7 |
CREATE TABLE salario_empleados ( nombre text, pago_trimestral integer[], programacion text[][] ); |
Como puedes ver, un tipo de datos de array se nombra agregando corchetes [] al nombre del tipo de datos de los elementos del array. El comando anterior creará una tabla nombrada salario_empleados con una columna de tipo text(nombre), una matriz unidimensional de tipo integer(pago_trimestral), que representa el salario del empleado por trimestre, y una array bidimensional de text(programacion), que representa el horario semanal del empleado.
La sintaxis para CREATE TABLE permite especificar el tamaño exacto de las arrays, por ejemplo:
|
1 2 3 4 5 |
CREATE TABLE tictactoe ( cuadricula integer[3][3] ); |
Sin embargo, la implementación actual ignora los límites de tamaño de array proporcionados, es decir, el comportamiento es el mismo que el de las arrays de longitud no especificada.
La implementación actual tampoco impone el número declarado de dimensiones. Las arrays de un tipo de elemento en particular se consideran todas del mismo tipo, independientemente del tamaño o la cantidad de dimensiones. Entonces, declarar el tamaño de la array o el número de dimensiones CREATE TABLE es simplemente documentación; no afecta el comportamiento en tiempo de ejecución.
Tipos compuestos
Un tipo compuesto representa la estructura de una fila o registro; es esencialmente solo una lista de nombres de campo y sus tipos de datos. PostgreSQL permite que los tipos compuestos se usen en muchas de las mismas formas en que se pueden usar los tipos simples. Por ejemplo, una columna de una tabla puede declararse de tipo compuesto.
Puedes definir tipos compuestos de la siguiente manera:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TYPE complex AS ( r double precision, i double precision ); CREATE TYPE inventario_articulos AS ( nombre text, proovedor_id integer, precio numeric ); |
La sintaxis es comparable a CREATE TABLE, excepto que solo se pueden especificar nombres y tipos de campo; sin restricciones (tal como NOT NULL). Ten en cuenta que la palabra AS clave es esencial; sin ella, el sistema pensará que CREATE TYPE se trata de un tipo diferente de comando y obtendrás errores de sintaxis extraños.
Tipos rango
Los tipos de rango son tipos de datos que representan un rango de valores de algún tipo de elemento (llamado subtipo de rango). Por ejemplo, se pueden usar rangos de timestamp para representar los rangos de tiempo que se reserva para una sala de reuniones. En este caso, el tipo de datos es tsrange(abreviatura de “rango de marca de tiempo”) y timestamp es el subtipo. El subtipo debe tener un orden total para que esté bien definido si los valores de los elementos están dentro, antes o después de un rango de valores.
Los tipos rango son útiles porque representan muchos valores de elementos en un solo valor de rango y porque conceptos como rangos superpuestos se pueden expresar claramente. El uso de rangos de fecha y hora para fines de programación es el ejemplo más claro; pero también pueden ser útiles los rangos de precios, los rangos de medición de un instrumento, etc.
Cada tipo de rango tiene un tipo multirango correspondiente. Un rango múltiple es una lista ordenada de rangos no contiguos, no vacíos y no nulos. La mayoría de los operadores de rango también trabajan en rangos múltiples y tienen algunas funciones propias.
Tipos dominio
Un dominio o domain es un tipo de datos definido por el usuario que se basa en otro tipo subyacente . Opcionalmente, este tipo puede tener restricciones que restrinjan sus valores válidos a un subconjunto de lo que permitiría el tipo subyacente. De lo contrario, se comporta como el tipo subyacente; por ejemplo, cualquier operador o función que se pueda aplicar al tipo subyacente funcionará en el tipo de dominio. El tipo subyacente puede ser cualquier tipo base integrado o definido por el usuario, tipo de enumeración, tipo de matriz, tipo compuesto, tipo de rango u otro dominio.
Por ejemplo, podríamos crear un dominio sobre enteros que acepte solo enteros positivos:
|
1 2 3 4 5 6 |
CREATE DOMAIN posint AS integer CHECK (VALUE > 0); CREATE TABLE mitabla (id posint); INSERT INTO mitabla VALUES(1); -- works INSERT INTO mitabla VALUES(-1); -- fails |
Cuando se aplica un operador o una función del tipo subyacente a un valor de dominio, el dominio se reduce automáticamente al tipo subyacente. Así, por ejemplo, se considera que el resultado de mitabla.id – 1 es de tipo integer no posint. Podríamos escribir (mitabla.id – 1)::posint para devolver el resultado a posint, lo que provocaría que se vuelvan a verificar las restricciones del dominio. En este caso, eso daría como resultado un error si la expresión se hubiera aplicado a un id valor de 1. Se permite asignar un valor del tipo subyacente a un campo o variable del tipo de dominio sin escribir una conversión explícita, pero las restricciones del dominio será revisado.
Tipos identificadores de objetos
PostgreSQL utiliza internamente los identificadores de objetos (OID) como claves principales para varias tablas del sistema. El tipo oid representa un identificador de objeto. También hay varios tipos de alias para oid, cada uno con su nombre.
El tipo oid se implementa actualmente como un entero de cuatro bytes sin signo. Por lo tanto, no es lo suficientemente grande para proporcionar unicidad en toda la base de datos en bases de datos grandes, o incluso en tablas individuales grandes.
El tipo oid en sí tiene pocas operaciones más allá de la comparación. Sin embargo, se puede convertir a entero y luego manipular usando los operadores enteros estándar. (Ten cuidado con la posible confusión entre firma o signed y no firma o unsigned si haces esto).
Los tipos de alias de OID no tienen operaciones propias excepto las rutinas de entrada y salida especializadas. Estas rutinas pueden aceptar y mostrar nombres simbólicos para objetos del sistema, en lugar del valor numérico bruto que oid usaría. Los tipos de alias permiten una búsqueda simplificada de valores OID para objetos. Por ejemplo, para examinar las filas pg_attribute relacionadas con una tabla mitabla, se podría escribir:
|
1 2 3 |
SELECT * FROM pg_attribute WHERE attrelid = 'mitabla'::regclass; |
En vez de:
|
1 2 3 4 |
SELECT * FROM pg_attribute WHERE attrelid = (SELECT oid FROM pg_class WHERE relname = 'mitabla'); |
Si bien eso no se ve tan mal por sí mismo, todavía está demasiado simplificado. Se necesitaría una subselección mucho más complicada para seleccionar el OID correcto si hay varias tablas nombradas mitabla en diferentes esquemas. El convertidor regclass de entrada maneja la búsqueda en la tabla de acuerdo con la configuración de la ruta del esquema, por lo que hace lo “correcto” automáticamente. De manera similar, convertir el OID de una tabla en regclass es útil para la visualización simbólica de un OID numérico.
Veamos a continuación una tabla con los tipos identificadores objetos:
| Nombre | Referencias | Descripción | Ejemplo de valor |
| oid | any | Identificador de objeto numérico | 564182 |
| regclass | pg_class | Nombre de la relación | pg_type |
| regcollation | pg_collation | Nombre de colación | “POSIX” |
| regconfig | pg_ts_config | Configuración de búsqueda de texto | english |
| regdictionary | pg_ts_dict | Diccionario de búsqueda de texto | simple |
| regnamespace | pg_namespace | Nombre del espacio de nombres | pg_catalog |
| regoper | pg_operator | Nombre del operador | + |
| regoperator | pg_operator | Operador con tipos de argumento | *(integer,integer)o-(NONE,integer) |
| regproc | pg_proc | Nombre de la función | sum |
| regprocedure | pg_proc | Función con tipos de argumento | sum(int4) |
| regrole | pg_authid | Nombre del rol | smithee |
| regtype | pg_type | Nombre del tipo de datos | integer |
Todos los tipos de alias de OID para objetos que están agrupados por espacio de nombres aceptan nombres calificados de esquema y mostrarán nombres calificados de esquema en la salida si el objeto no se encuentra en la ruta de búsqueda actual sin estar calificado.
Tipo pg_lsn
El tipo de datos pg_lsn se puede utilizar para almacenar datos LSN (Log Sequence Number), que es un puntero a una ubicación en el WAL. Este tipo es una representación XLogRecPtr y un tipo de sistema interno de PostgreSQL.
Internamente, un LSN es un número entero de 64 bits que representa una posición de byte en el flujo de registro de escritura anticipada. Se imprime como dos números hexadecimales de hasta 8 dígitos cada uno, separados por una barra oblicua; por ejemplo, 16/B374D848.
El tipo pg_lsn admite los operadores de comparación estándar, como = y >. Se pueden restar dos LSN usando el operador –; el resultado es el número de bytes que separan esas ubicaciones de registro de escritura anticipada.
Además, la cantidad de bytes se puede sumar y restar de LSN usando los operadores +(pg_lsn,numeric) y -(pg_lsn,numeric), respectivamente. Ten en cuenta que el LSN calculado debe estar en el rango de tipo pg_lsn, es decir, entre 0/0 y FFFFFFFF/FFFFFFFF.
Pseudotipos
El sistema de tipos de PostgreSQL contiene una serie de entradas de propósito especial que se denominan colectivamente pseudotipos. Un pseudotipo o pseudo-type no se puede usar como un tipo de datos de columna, pero se puede usar para declarar el argumento de una función o el tipo de resultado. Cada uno de los pseudotipos disponibles es útil en situaciones en las que el comportamiento de una función no se corresponde simplemente con tomar o devolver un valor de un tipo de datos SQL específico.
| Nombre | Descripción |
| any | Indica que una función acepta cualquier tipo de datos de entrada. |
| anyelement | Indica que una función acepta cualquier tipo de datos. |
| anyarray | Indica que una función acepta cualquier tipo de datos de matriz. |
| anynonarray | Indica que una función acepta cualquier tipo de datos que no sean de matriz. |
| anyenum | Indica que una función acepta cualquier tipo de datos de enumeración. |
| anyrange | Indica que una función acepta cualquier tipo de datos de rango. |
| anymultirange | Indica que una función acepta cualquier tipo de datos de rango múltiple. |
| anycompatible | Indica que una función acepta cualquier tipo de datos, con promoción automática de múltiples argumentos a un tipo de datos común. |
| anycompatiblearray | Indica que una función acepta cualquier tipo de datos de matriz, con promoción automática de varios argumentos a un tipo de datos común. |
| anycompatiblenonarray | Indica que una función acepta cualquier tipo de datos que no sea de matriz, con promoción automática de varios argumentos a un tipo de datos común. |
| anycompatiblerange | Indica que una función acepta cualquier tipo de datos de rango, con promoción automática de múltiples argumentos a un tipo de datos común. |
| anycompatiblemultirange | Indica que una función acepta cualquier tipo de datos de rango múltiple, con promoción automática de múltiples argumentos a un tipo de datos común. |
| cstring | Indica que una función acepta o devuelve una cadena C terminada en nulo. |
| internal | Indica que una función acepta o devuelve un tipo de datos interno del servidor. |
| language_handler | Se declara que un controlador de llamadas de lenguaje de procedimiento devuelve language_handler. |
| fdw_handler | Se declara que un controlador contenedor de datos foráneos devuelve fdw_handler. |
| table_am_handler | Se declara que un controlador de método de acceso a la tabla devuelve table_am_handler. |
| index_am_handler | Se declara un controlador de método de acceso de índice para devolver index_am_handler. |
| tsm_handler | Se declara un controlador de método tablesample para devolver tsm_handler. |
| record | Identifica una función que toma o devuelve un tipo de fila no especificado. |
| trigger | Una función de disparo se declara para devolver trigger. |
| event_trigger | Se declara que una función de activación de eventos devuelve event_trigger. |
| pg_ddl_command | Identifica una representación de comandos DDL que está disponible para activadores de eventos. |
| void | Indica que una función no devuelve ningún valor. |
| unknown | Identifica un tipo aún no resuelto, por ejemplo, de un literal de cadena sin decorar. |
Las funciones codificadas en el lenguaje de programación C (ya sean integradas o cargadas dinámicamente) se pueden declarar para aceptar o devolver cualquiera de estos pseudotipos. Depende del autor de la función asegurarse de que la función se comporte de forma segura cuando se utiliza un pseudotipo como tipo de argumento.
Bien, estos son todos los Tipos de Datos que tiene PostgreSQL, recuerda que hemos usado como guía la documentación oficial de PostgreSQL, por ello es una información veráz y oficial.
Conclusión
En este post que consta de 3 partes has conocido los Tipos de Datos en PostgreSQL, seguro no llegues a usar todos ellos, pero lo importante es que domines los necesarios, esto solo puedes lograr prácticando PostgreSQL, ya sea creando poryectos personales o para clientes.
Nota
- No olvides que debemos usar la Tecnología para hacer cosas Buenas por el Mundo.
Síguenos en nuestras Redes Sociales para que no te pierdas nuestros próximos contenidos.
- PostgreSQL
- 17-07-2023
- 23-07-2023
- Crear un Post - Eventos Devs - Foro





 Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
Seguimos trabajando las 24 horas del día para brindarte la mejor experiencia en la comunidad.
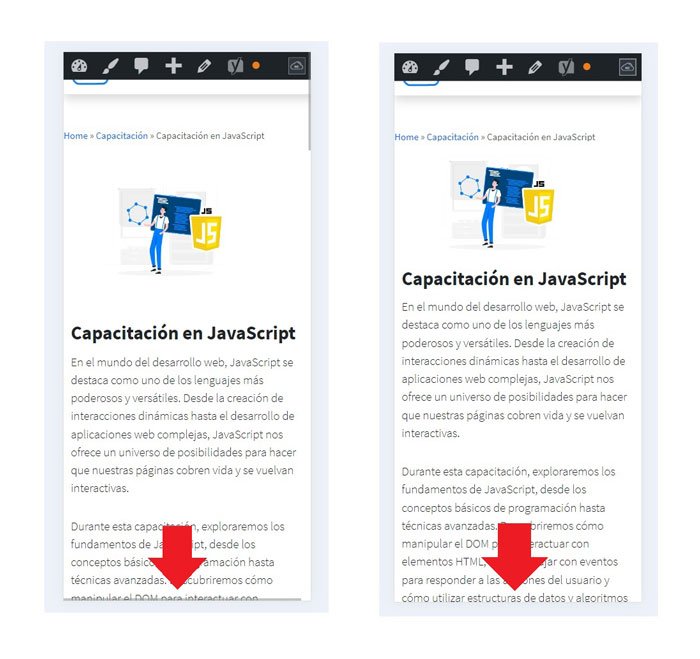 Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.
Hemos corregido el problema y ahora la web no muestra esa barra horizontal y se ve en su tamaño natural.
Seguimos trabajando las 24 horas del día, para mejorar la comunidad.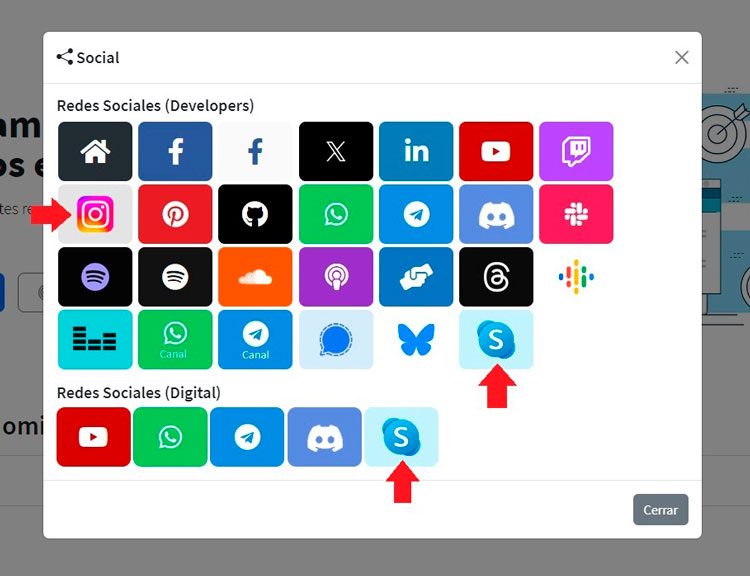 Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
Seguimos trabajando las 24 horas y 365 días del año para mejorar tu experiencia en la comunidad.
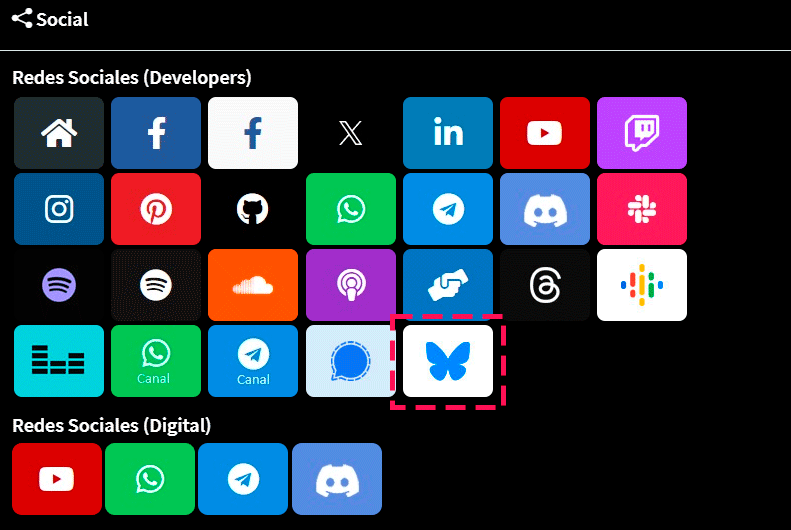
 Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.
Seguimos trabajando para brindarte le mejor experiencia en Nube Colectiva.

Social
Redes Sociales (Developers)
Redes Sociales (Digital)