



En esta página:
Demo Github
En la primera parte de este tutorial llamado Creando Nuestro Primer Modelo de Machine Learning (Aprendizaje Automático) con TensorFlow – Parte 1, preparamos los datos del cliente que nos brindo para el proyecto, también creamos una capa llamada capa_a y por último creamos el modelo correspondiente, en esta parte 2 y última, compilaremos y entrenaremos el modelo, asimismo mostraremos estadísticas del entrenamiento del modelo, usaremos nuestro modelo para predecir datos y verificaremos la precisión de nuestro modelo, vamos con ello.
Partes
- Parte 1
- Parte 2 (Final – Código Fuente en GitHub)

Antes de continuar te invito a leer los siguientes artículos:
- Que es Machine Learning, Historia y otros detalles
- Que es TensorFlow y Otros Detalles
- 5 Buenas Prácticas de Machine Learning para Desarrolladores en Python
- Tendencias que se darán en Machine Learning este 2020
- Como esta presente la Inteligencia Artificial y el Machine Learning en nuestra vida cotidiana
- Como utilizan estas 5 Grandes Empresas el Aprendizaje Automático (Machine Learning)
- Conceptos del Trabajo con Material Design y Machine Learning en Android – Parte 1
- Creando una Aplicación Android que responda ante comandos de Voz mediante Inteligencia Artificial y Machine Learning – Parte 1
Asimismo te invito a escuchar el Podcast: “Con Que Lenguaje De Programación Comenzar Para El Desarrollo Web”:
| Spotify: | Sound Cloud: |
 |
 |

Bien ahora continuemos con el Post: Creando Nuestro Primer Modelo de Machine Learning (Aprendizaje Automático) con TensorFlow – Parte 2 (Final).
Compilación del Modelo
Antes de pasar a entrenar el modelo, debemos de compilarlo y proporciona 2 funciones importantes, la función de perdida, que es una forma de medir que tan lejos están las predicciones del resultado deseado (La diferencia medida se llama pérdida).
La otra función es la función de optimizador, la cual es una forma de ajustar los valores internos internos para reducir la pérdida.
|
1 2 3 4 5 |
# Compilamos el modelo modelo.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1)) |
Cuando pasemos a entrenar el modelo, usaremos model.fit y le pasaremos algunos parámetros de la compilación del modelo anterior, para calcular primer la pérdida en cada punto y luego mejorarla. El acto de calcular la pérdida actual de un modelo y luego mejorarlo es precisamente lo que es el entrenamiento.
En el entrenamiento del modelo, la función de optimizador se usa para calcular los ajustes a las variables internas del modelo, el objetivo es ajustar las variables internas hasta que el modelo (el cual es una función matemática) refleje la ecuación real para convertir monto_invertido a suscriptores_ganados.
TensorFlow realiza un análisis numérico para realizar este ajuste y toda esta complejidad está oculta para los desarrolladores y no entraremos a detallar ello, algo que si es útil saber es:
- La función de pérdida (error cuadrático medio) y el optimizador (Adam) usados en la compilación son estándares para modelos simples como el que estamos usando en este tutorial, hay otros estándares más complejos para otros tipos de modelos.
- Una parte del optimizador en la que quizás debes pensar al crear sus modelos es la tasa de aprendizaje (puedes ver el valor 0.1 al final del código anterior). Este valor es el tamaño de paso que se toma al ajustar los valores en el modelo, si el valor es demasiado pequeño, se necesitarán demasiadas iteraciones para entrenar el modelo y si el valor es demasiado grande y la precisión disminuye, encontrar un buen valor a menudo implica algo de prueba y error, pero el rango suele estar entre 0,001 (valor predeterminado) y 0,1.
Entrenando el Modelo
En el proceso de entrenamiento, el modelo toma los valores del monto invertido en marketing que nos brindo el cliente y que mencionamos en la Parte 1 de este tutorial, luego de tomar los valores del monto invertido en marketing, realiza un cálculo usando las variables internas actuales ( llamadas weights) y los valores de salida que se supone que son los Nuevos Suscriptores Ganados.
Dado que los weights se establecen al inicio de manera aleatoria, la salida no se acercará al valor correcto, la diferencia entre la salida real y la salida deseada se calcula utilizando la función de pérdida y la función del optimizador indica como se deben ajustar los weights.
Todo este ciclo de cálculo, comparación y ajuste se controla mediante el método de ajuste, el prime argumento son las entradas, el segundo argumento son las salidas deseadas.
El argumento epochs especifica cuantas veces se debe ejecutar este ciclo y el argumento verbose controla la cantidad de salida que produce el método.
|
1 2 3 4 5 |
# Entrenamos el modelo entrenar_modelo = modelo.fit(X_train, y_train, epochs = 1000, verbose = False) print("Entrenamiento Terminado.") |
La siguiente tarea es opcional, es decir si deseas la puedes realizar o no, en esta tarea vamos a mostrar estadísticas de entrenamiento.
Estadísticas de Entrenamiento
En el código anterior, donde entrenamos nuestro modelo, el método fit(), devuelve un objeto histórico el cual podemos usar para hacer un trazo que muestre como disminuye la pérdida de nuestro modelo después de cada época de entrenamiento. Una perdida alta significa que el valor de los nuevo suscriptores ganados que predice el modelo, está lejos del valor correspondiente de los suscriptores reales ganados.
|
1 2 3 4 5 6 7 |
# Creamos un gráfico para mostrar estadísticas del entrenamiento import matplotlib.pyplot as plt plt.xlabel('Época') plt.ylabel("Magnitud de Pérdida") plt.plot(entrenar_modelo.history['loss']) |
Si ejecutamos el código anterior, obtenemos un gráfico en Jupyter Notebook que muestra una estadística del entrenamiento del modelo.
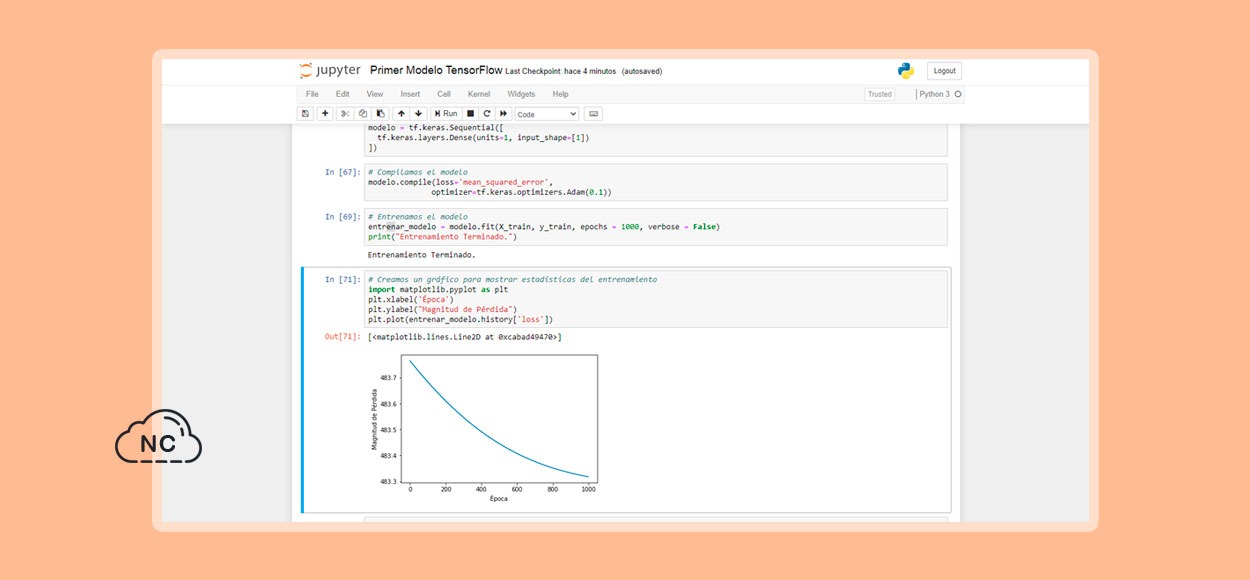

En el gráfico anterior podemos ver que nuestro modelo mejora de manera rápida al principio y luego tiene una mejora constante y lenta hasta que está muy cerca de ser perfecto hacia el final.
Prediciendo Datos
Ahora que tenemos un modelo el cual ha sido entrenado para aprender la relación entre monto_invertido y suscriptores_ganados, podemos usar el método de predicción para calcular los nuevos suscriptores ganados para un monto o presupuesto de marketing previamente conocido o desconocido.
Por ejemplo, si el valor de monto_invertido es de 85 mil dólares, cual crees que será el resultado suscriptores_ganados ?
Podemos adivinar antes de ejecutar el siguiente código o consulta.
|
1 2 3 4 5 6 7 |
# Predicción usando el modelo print(modelo.predict([80.0])) # Resultado [[210.38962]] |
El resultado es [[210.38962]] y la respuesta correcta sería 85 * 2 + 40 = 210, por lo tanto nuestro modelo está funcionando muy bien.
Ahora predeciremos etiquetas para todos los puntos de datos de prueba y los compararemos con sus puntos de datos reales.
|
1 2 3 4 5 6 7 8 9 10 |
# Predicción de los puntos de datos de prueba y_pred = modelo.predict(X_test) print('Valores Pedecidos') print(y_test,' ',y_pred.reshape(1,-1)) # Obtenemos Valores Pedecidos [177. 209.] [[174.39508 210.38962]] |
A continuación haremos una verificación del modelo mediante una métrica de rendimiento.
Verificando la precisión del Modelo
Para verificar mi modelo haré uso de r2_score(valor r cuadrado) o r2_score(r-squared value). R² es una estadística que nos proporcionará información sobre la bondad de ajuste de nuestro modelo.
En la regresión, el coeficiente de determinación R² es una medida estadística de qué tan bien se aproximan las predicciones de la regresión a los puntos de datos reales. Un R2 de 1 indica que las predicciones de regresión se ajustan perfectamente a los datos.
|
1 2 3 4 5 6 7 8 |
# Verificamos la precisión del modelo from sklearn.metrics import r2_score r2_score(y_test, y_pred) # Resultado 0.9829753890403481 |
El resultado de precisión del modelo es 0.9829753890403481 y como puedes apreciar, el r2_score del modelo es casi = 1, esto significa que nuestro modelo esta prediciendo con buena precisión.
Bien y con esto hemos terminado, hemos realizado diferentes tareas con nuestro primer modelo de Machine Learning (Aprendizaje Automático) con TensorFlow. Al inicio de esta última parte he colocado un enlace al repositorio GitHub en donde he alojado el código fuente del proyecto, asimismo he colocado una Demo en todas las partes de este tutorial.
Conclusión
En este tutorial hemos aprendido muchas cosas como la creación de nuestro primer modelo de Machine Learning (Aprendizaje Automático) con TensorFlow, hemos aprendido a entrenar y verificar su precisión de nuestro modelo, entre otras tareas. Conforme vayas practicando, obtendrás más experiencia y lograrás hacer tareas más complejas con TensorFlow.
Nota (s)
- Los pasos mencionados a lo largo de este tutorial, pueden cambiar o continuar, esto no depende de mi, si no de TensorFlow y Python, que suelen cambiar los pasos de configuración en futuras versiones.
- No olvides que debemos usar la Tecnología para hacer cosas Buenas por el Mundo.
Síguenos en nuestras Redes Sociales para que no te pierdas nuestros próximos contenidos.